

O texto abaixo não é de minha autoria. É um texto que li e achei muito interessante - Clique Aqui - Last updated: 2011/01/06 Adabas Version 8.2.2 Mainframe James Poole
O correto dimensionamento do dataset de Work é simples, mas pode ter um impacto significativo no desempenho do banco de dados, bem como evitar problemas.
No geral, os tempos ideais de I/O devem sempre ser considerado para do dataset de Work como Work Part 1 pode ser um grande gargalo em potencial.
O que não é coberto neste artigo:
Parte 4 Work (área de processamento de transações distribuídas; ADARUN LDTP; Adabas Manager)
ADARUN NWORK1 BUFFERS melhorar a Work Parte desempenho um write (altamente recomendado)
Questões não de mainframe
Geral
O dataset de Work basicamente é dividido em três áreas, cada uma com uma função bem diferente, cada uma deve ser feito sob medida separadamente. Os básicos três áreas:
Enter SYSAOS
(Nota isso também pode ser realizado através de lote ADADBS OPERCOM DRES)
O tamanho total do dataset de Work em cilindros é a soma de blocos para cada um dos três domínios mais o número de blocos por uma faixa mais, tudo dividido pelo número de blocos por cilindro.
Por exemplo nos exemplos e números (8393 blockSize, 2 blocos por trilha, 30 blocos por cilindro) acima:
A partir dos manuais.
1 - Crie o novo dataset Work com o número correto de cilindros.
2 - ADAFRM é o utilitário que formata uma nova Work. Por exemplo: ADAFRM WORKFRM SIZE=3000,DEVICE=8393
3 - Shutdown o banco de dados (Nota a função ADADEF NEWWORK não pode ser executada se um autorestart exite pendente)
4 - Execute ADADEF NEWWORK. NOTA: A antiga Work deve ser especificada neste no JCL (ou alocar uma obra fictícia do mesmo tamanho e tipo de dispositivo, formatado). ADADEF atualiza GCB do Associator com o novo tamanho e tipo de dispositivo. Por exemplo: ADADEF Newwork WORKSIZE = 3000, WORKDEV = 8393
5 - Atualize na proc do banco o novo dataset de Work;
6 - Coloque no ar o banco de dados;
Dimensionamento a Work - Parte 1 (Adarun LP =)
A Work parte 1 é usado para registrar todas as atualizações do banco de dados para fins de recuperação e backouts.
- Tamanho mínimo: 200 blocos
- Tamanho máximo: Blocos de 2G blocos
Não há problemas da Work Parte 1 ser muito grande. Mesmo com rearranque automático, um método de busca binária é usado para encontrar o bloco mais antigo para fins de reinício.
Se o Work da Parte 1 é muito pequeno.
- Increased Buffer Flushes (desempenho)
- Risco de síncronas buffer Libera (Performance)
- Os usuários que receberem o Response Code 9 sub código 15 ou Código de Resposta 8 (Work Wraparound, veja abaixo)
Bottom Line: Dataset Work maior proporcionar um melhor desempenho, bem como diminuir o risco de problemas relacionadas com a Work (veja abaixo).
O que está contido na Work Parte 1 (Não é uma lista completa)
Before Images (registro comprimido dos dados antes da mudança), After Images (registro dos dados comprimido após a mudança), (Descriptor Valor Tabela de imagem antes e depois de descritores alterado), ET records (Transação End), Checkpoint records, Before Image of Associator Index blocks, Registros Especiais (início/fim de descargas do buffer, comando, etc). Produtos adicionais também podem utilizar a Work Parte 1 como Event Replicator.
Trabalho envolventes e Código de Resposta 9 sub código 15
A partir do Adabas Versão 8.2, cerca de 25% da Work Parte 1 está reservada para os conteúdos descritos acima. A área restante é utilizado no caso de autorestart (user backout, Adabas backout, ou para start/autorestart do banco). Esse percentual pode mudar com as novas versões do Adabas. Consulte a seção neste artigo sobre como determinar a porcentagem para novos lançamentos.
Como ocorrem nos updates do usuário e do ET dos usuários, os dados são gravados na Work Parte 1 de uma forma envolvente. Uma vez que as atualizações envolventes, é feita uma verificação para ver se os dados a serem substituídos foi ET'd e se ele foi liberado para Associator e Data Storage (ou seja, o buffer liberado). Se não foi Buffer Flushed, então um Buffer Flushed é emitido. Se o usuário a ser substituído não foi ET'd, esse usuário recebe um response code 9 subcode 15 é lançada para seu elemento fila do usuário para a sua próxima chamada Adabas. O utilizador recebe o código de resposta 9-15 não é necessariamente a causa mas a vítima. Se um usuário executa atualizações suficientes sem ET (e não excede um outro recurso, como a fila de Espera ou limite de tempo), então eles se pode receber um código de resposta 9-15. Veja mais Clique Aqui
Embora muitos fatores possam resultar no código de resposta 9-15, se o código de resposta 9-15 está ocorrendo e não é devido à extrema ou má codificação de aplicações, é um indicador de que Work Part 1 deve ser aumentada.
Uma escola de pensamento sobre o dimensionamento da Work Part 1 diz que o Work Part 1 deve ser quatro vezes (em volta de 25%) do montante máximo de transações correntes vezes os updates média por tempo de transação dos bloco da Work medio por atualização. Este seria um dimensionamento mínimo. Note-se que o dimensionamento de ADARUN NISNHQ afeta essa fórmula.
Outra escola de pensamento sobre o dimensionamento da Work Part 1 diz que, em um cenário de pior caso, a área pode ser dimensionada como o número máximo de transações simultâneas vezes o ADARUN TT= dividido pelo tempo médio de uma I/O da Work (ver estatísticas de cache abaixo como obter o tempo médio de trabalho I/O). Note-se que o dimensionamento de ADARUN TT afeta essa fórmula.
Fatores (alterações no ambiente das aplicações) podem aumentar cenários de Response Code 9-15 9-15 (ou aumentam a necessidade de aumentar Work Part 1) podem incluir, mas não se limitando ao seguinte:
- Aumente o Limite de Tempo Maior transação (ADARUN TT=)
- Aumento atualizações por transação (ADARUN NISNHQ =)
- Aumento comprimido tamanhos de registro, o aumento descritores e atualizações de descritores
- Aplicações batch que atualizam sucessivamente menores valores de descritores (aumenta blocos splits)
Uma Work Part 1 pequeno Aumenta Buffer Flushes #
Veja a explicação acima sobre o que acontece no local de Work Wraparound. Há gráficos que mostram como o aumento Work Parte1 diminui descargas do buffer (e melhora o desempenho do banco de dados), mas eu não poderia facilmente copiar gráficos Xcel neste meio.
Aumentando a Work Part 2 (Adarun LWKP2=)
A Work Part 2 é usado como uma área de rascunho baseado em disco para processar o comando Sx (FIND). A quantidade de Work Part 2 usada por qualquer comando único é apenas para a duração desse comando no segmento Adabas. Vários comandos Sx em vários segmentos usará simultaneamente a Work Part 2. O dimensionamento de ADARUN LWP e ADARUN LS afeta diretamente o quanto esta área é usada (como esses parâmetros aumentado, o uso da Work Part 2 pode diminuir).
- Tamanho mínimo: 0 blocos
- Tamanho máximo: 16,7 milhões de blocos
- Tamanho padrão: (veja abaixo) NÃO USE default
Uma tabela interna Adabas requer um byte de armazenamento para cada Work part 2 bloco.
Se a Work Part 2 é muito grande pode afetar os requisitos de memória (1 byte por Work Part 2). Se o trabalho da Parte 2 é armazenado em cache (ADARUN CWORK2FAC=), então um grande Work Part 2, com uma grande CWORK2FAC correspondente = pode voltar a afetar os requisitos de memória.
Note-se que até mesmo a utilização de uma pequena CWORK2FAC (1%) pode indicar uso da Work Part 2.
Se a Work Part 2 é muito pequena.
Ocorre atraso do comando Sx (FIND)
Response Code 74 (Work Part 2 está cheia)
O código da aplicação deficiente pode afetar o tamanho da área. Por exemplo, os programas podem estar fazendo desnecessariamente grandes pesquisas complexas (o que inclui pesquisas em não descritores).
Padrão Dimensionamento de Work Part 2
- Work2 é work part 2 que necessita de espaço em blocos.
- BLKSIZE é o tamanho do bloco do dispositivo dataset da Work
- RECORDS é o número de registros no arquivo com a maioria dos registros. Este número é igual TOPISN - MINISN + 1, em que é o mais alto TOPISN ISN atualmente utilizado no arquivo. MINISN é o menor ISN usado no arquivo. Note-se que TOPISN é avaliada na inicialização do banco de dados.
Parm Error 18 na Inicialização do banco Adabas
Isso ocorre principalmente quando o tamanho padrão da Work part 2 é usado. O cenário é o banco de dados entra no ar e a Work Part 2 foi dimensionada pela maior TOPISN existente. Em algum momento durante a sessão Adabas, um arquivo no banco de dados aumenta significativamente o TOPISN (via inserções de registro ou carregando um arquivo muito maior para o banco de dados). A próxima vez que o banco de dados for iniciado, uma tentativa é redimensionar Work part 2 pelo TOPISN maior e não há espaço no conjunto de dados Work para qualquer parte Work Work 2 ou a Work part 3 ficaram com menos de 50 blocos. Portanto, é importante que a Work part 2, LWKP2 =, é sempre usado.
Comando Sx (Find)
Nota: Os comandos complexos não são selecionados a partir da Command Queue (CQ) para o segmento Thread do Adabas a menos que 50% da Work part 2 esteja disponível. Portanto, o tamanho da Work part 2 em duas vezes é necessário para otimizar o processamento de comando de transferência. Esta é uma simples filosofia de negociação uma pequena quantidade de espaço em disco para o desempenho. Tipo de comando (complexo, atualização, simples) é determinada na rotina para ligação antes do comando é passado para Adabas. A decisão para comandos complexos é baseada nos comandos Sx cuja o comprimento Search Buffer excede um determinado constante. Devido à construção do comando Sx pelo Natural, todos comandos Sx/FIND no Natural são tratados como complexo (para fins de seleção de comando).
Fórmula para Tamanho do Work Part 2
- Work2 é a Work part 2 é o espaço requerido em blocos;
- BLKSIZE é o tamanho do bloco do dispositivo do dataset de Work
- RECORDS é o número de registros no arquivo com a maioria dos registros. Este número é igual TOPISN - MINISN + 1, em que é o mais alto TOPISN ISN atualmente utilizado no arquivo. MINISN é o menor ISN usado no arquivo. * S é o número de comandos complexos simultâneas
S pode ser determinado através de estatísticas de encerramento do Adabas como o percentual de Sx comandos vezes o número de threads ativas (por exemplo. Se 10% dos comandos são Sx e há 10 threads ativas, então S seria de aproximadamente um valor de 1).
Aumentando a Work Part 3
A Work Part 3 é usado para listas de ISN resultantes do comando Sx/Find. Listas permanecem em Work Part 3 até que o último ISN é processado ou até que seja liberado pelo usuário (por exemplo,. comandos Via RC ou CL). Neste último caso, a lista ISN foi marcado (por exemplo, Opção. Comando 1 = H, ou o Natural "Reter o").
- Tamanho mínimo: 50 blocos (mais PARM-ERROR 18 no start do banco de dados)
- Tamanho máximo: desconhecido
O tamanho do Work Part 3 é o que resta em WORKSIZE depois da Work Part 1 e Work Part 2 foi feita sob medida. É fundamental que o dimensionamento do Work Part 1 e 2 não interferem com esta área.
Uma tabela interna do Adabas requer quatro bytes de armazenamento para cada block na Work part 3.
Se a Work Part 3 é muito grande pode afetar os requisitos de memória (4 bytes por Work Part 3). Se a Work Part 3 está em cache (ADARUN CWORK3FAC=), então um grande Work Part 3 com uma grande CWORK3FAC correspondente = pode voltar a afetar os requisitos de memória.
Note-se que até mesmo a utilização de uma pequena CWORK3FAC (1%) pode indicar uso da Work Part 3.
Se a Work Part 3 é muito pequeno um usuário receberá Response Code 73. O código da aplicação deficiente pode afetar o tamanho da área. Por exemplo os programas podem manter listas de ISN e não liberá-los. Consultas do tipo SQL pode criar extremamente grandes listas de ISN. Uso de grande algoritmo Sx/FIND pode esgotar nesta área (2 ou mais descritores, um valor cada).
Fórmula para Tamanho do Work Part 3
Existem várias fórmulas possíveis para usar em dimensionar esta área.
- WORK3 é a Work part 3 requerida de espaço em blocos
- ISN.LIST.SIZE é o número médio de ISNS por lista
- AWBU é a parte de work média 3 blocos por lista (4 bytes por ISN)
- BLKSIZE é o tamanho do bloco do dispositivo do conjunto de dados Work
- NU é o ADARUN NU = valor. Isso pressupõe uma lista por usuário, uma bloco por lista na Work3. Ou pode-se usar a Highwater alta de NU.
- IU é as listas média ISN por usuário
- HIWATER.LI é a Highwater alta para a tabela de listas de ISN (ADARUN LI)
- NSISN é o valor ADARUN NSISN, o número de ISN do mantidos no quadro de entrada por ISN Listas
Note-se que o aumento NSISN diminuirá o uso da Work Part 3.
Aumentar o tamanho de bloco do dataset de Work
O tamanho do bloco do dataset de Work pode ser aumentado independentemente do Associator e do Datastorage (note que o PLOG precisara ser alteradas). Não pode haver ganho de desempenho significativo, aumentando o tamanho do bloco (redução do I/O) e quaisquer questões negativas são raras. Alterando o tamanho do bloco é o mesmo que o aumento do dataset de Work (ver acima). NOTA. O PLOG também terá que ter uma mudança no tamanho do bloco. Isso afetará o ADARUN DUALPLD e parms DUALPLS (menos blocos por o mesmo tamanho do PLOG).
Se o tamanho total do dataset de work é mantido, mas o tamanho do bloco foi aumentado, em seguida, os parms ADARUN de LP e LWKP2 terá de ser ajustado para baixo. A outra abordagem é aumentar o dataset de Work ao mesmo tempo do aumento do tamanho de bloco.
Dividindo o dataset de Work em vários volumes
Historicamente, em alguns locais de trabalho já vi vantagens de desempenho em dividir em três partes a work em vários volumes. Outras soluções para isso são a cache do Work Part 2 e 3 (ver abaixo). Além disso, a utilização do PAV (Parallel Access Volumes) poderia eliminar a necessidade deste.
Work Caching Part 2 e 3
ADARUN CWORK2FAC e CWORK3FAC
Veja outras fontes sobre os tipos de cache, relatórios, problemas, entre outros. Um cache mínima de 1% é recomendado para cada um como este fornece muitas estatísticas úteis em IO de por área Work, tempos de I/O relativos, etc. O seguinte é uma exposição de cache amostra (disponível via comandos do operador, AOS, lote ADADBS OPERCOM, ou estatísticas de desligamento do banco de dados.
Checkilst para melhorar o desempenho da Work
- O dimensionamento correto da parte 1, 2, 3 Work (ver acima)
- Grandes blocos
- Cache da Work Part 2 e 3
- ADARUN NWORK1BUFFERS (geralmente aumentem)
- (Parallel Access Volumes) do PAV
- Sintonia geral dos discos do dataset de Work (i/o e do canal de contenção)
- O dimensionamento correto de LWP ADARUN e LS (geralmente aumentando)
- O dimensionamento correto de ADARUN NSISN (geralmente aumentando)
- O dimensionamento correto de ADARUN TT (geralmente diminui)
Determinando um ponto para Montagem da Work Part 1
Além da Software AG fornecer as informações, as seguintes rascunhos para uma maneira simples de verificar qual é o ponto envoltório é para as novas versões do Adabas.
- Criar um banco de dados dedicado para executar o teste para vários tamanhos de ADARUN LP (por exemplo, 200, 1000, 2000.)
- Crie um arquivo de registro grande (por exemplo, 100b campos, todos fixos, não descritores.). Tamanho do registro deve cerca fator em blocksize Work (por exemplo,. Work Blocksize de 5724, então o tamanho recorde de 1.300 bytes, 2 registros por bloco)
- Como o único usuário do banco de dados, execute um programa que insere registros no arquivo, contando o número de inserções de até um código de resposta 9 sub 15.
- Multiplique o número de inserções, vezes os registros por bloco; divida a Work Part 1 tamanho; então multiplicar por 100 (para um por cento) e que é o ponto aproximado envoltório.
O correto dimensionamento do dataset de Work é simples, mas pode ter um impacto significativo no desempenho do banco de dados, bem como evitar problemas.
No geral, os tempos ideais de I/O devem sempre ser considerado para do dataset de Work como Work Part 1 pode ser um grande gargalo em potencial.
O que não é coberto neste artigo:
Parte 4 Work (área de processamento de transações distribuídas; ADARUN LDTP; Adabas Manager)
ADARUN NWORK1 BUFFERS melhorar a Work Parte desempenho um write (altamente recomendado)
Questões não de mainframe
Geral
O dataset de Work basicamente é dividido em três áreas, cada uma com uma função bem diferente, cada uma deve ser feito sob medida separadamente. Os básicos três áreas:
+---+-------------------+----------------------------+
| 1 | ADARUN LP | Data Protection Area |
| 2 | ADARUN LWKP2 | ISN List Processing Area |
| 3 | remaining WORK | Resultant ISN Lists |
+---+-------------------+----------------------------+Enter SYSAOS
A Session monitoring
U Display resource utilization
W WORK status W O R K Dataset
+--------------------------------------------------------+
I Protection Area 83700 Blks I
I--------------------------------------------------------I
I Intermediate ISN Area 6000 Blks I
I--------------------------------------------------------I
I Resulting ISN Area 297 Blks I
I--------------------------------------------------------I
I Distributed Transaction Processing Area 0 Blks I
+--------------------------------------------------------+(Nota isso também pode ser realizado através de lote ADADBS OPERCOM DRES)
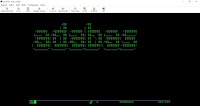
ADAN28 00044 2011-01-05 12:09:02 RESOURCE SIZE CURRENT HIGHWATER
ADAN28 00044 2011-01-05 12:09:02 WORK PART1 83700 0 49
ADAN28 00044 2011-01-05 12:09:02 WORK PART2 6000 0 7
ADAN28 00044 2011-01-05 12:09:02 WORK PART3 297 0 4AREA ADARUN PARM HIGH-WATER-MARK
-----------------------------------------------
Work Part1 LP = 83700 16398 ( 19 %)
Work Part2 LWKP2= 6000 0 ( 0 %)
Work Part3 -- = 297 3 ( 1 %)O tamanho total do dataset de Work em cilindros é a soma de blocos para cada um dos três domínios mais o número de blocos por uma faixa mais, tudo dividido pelo número de blocos por cilindro.
Por exemplo nos exemplos e números (8393 blockSize, 2 blocos por trilha, 30 blocos por cilindro) acima:
(83700 + 6000 + 297 + 2 + 1) / 30 = 3000 cylindersA partir dos manuais.
1 - Crie o novo dataset Work com o número correto de cilindros.
2 - ADAFRM é o utilitário que formata uma nova Work. Por exemplo: ADAFRM WORKFRM SIZE=3000,DEVICE=8393
3 - Shutdown o banco de dados (Nota a função ADADEF NEWWORK não pode ser executada se um autorestart exite pendente)
4 - Execute ADADEF NEWWORK. NOTA: A antiga Work deve ser especificada neste no JCL (ou alocar uma obra fictícia do mesmo tamanho e tipo de dispositivo, formatado). ADADEF atualiza GCB do Associator com o novo tamanho e tipo de dispositivo. Por exemplo: ADADEF Newwork WORKSIZE = 3000, WORKDEV = 8393
5 - Atualize na proc do banco o novo dataset de Work;
6 - Coloque no ar o banco de dados;
Dimensionamento a Work - Parte 1 (Adarun LP =)
A Work parte 1 é usado para registrar todas as atualizações do banco de dados para fins de recuperação e backouts.
- Tamanho mínimo: 200 blocos
- Tamanho máximo: Blocos de 2G blocos
Não há problemas da Work Parte 1 ser muito grande. Mesmo com rearranque automático, um método de busca binária é usado para encontrar o bloco mais antigo para fins de reinício.
Se o Work da Parte 1 é muito pequeno.
- Increased Buffer Flushes (desempenho)
- Risco de síncronas buffer Libera (Performance)
- Os usuários que receberem o Response Code 9 sub código 15 ou Código de Resposta 8 (Work Wraparound, veja abaixo)
Bottom Line: Dataset Work maior proporcionar um melhor desempenho, bem como diminuir o risco de problemas relacionadas com a Work (veja abaixo).
O que está contido na Work Parte 1 (Não é uma lista completa)
Before Images (registro comprimido dos dados antes da mudança), After Images (registro dos dados comprimido após a mudança), (Descriptor Valor Tabela de imagem antes e depois de descritores alterado), ET records (Transação End), Checkpoint records, Before Image of Associator Index blocks, Registros Especiais (início/fim de descargas do buffer, comando, etc). Produtos adicionais também podem utilizar a Work Parte 1 como Event Replicator.
Trabalho envolventes e Código de Resposta 9 sub código 15
A partir do Adabas Versão 8.2, cerca de 25% da Work Parte 1 está reservada para os conteúdos descritos acima. A área restante é utilizado no caso de autorestart (user backout, Adabas backout, ou para start/autorestart do banco). Esse percentual pode mudar com as novas versões do Adabas. Consulte a seção neste artigo sobre como determinar a porcentagem para novos lançamentos.
Como ocorrem nos updates do usuário e do ET dos usuários, os dados são gravados na Work Parte 1 de uma forma envolvente. Uma vez que as atualizações envolventes, é feita uma verificação para ver se os dados a serem substituídos foi ET'd e se ele foi liberado para Associator e Data Storage (ou seja, o buffer liberado). Se não foi Buffer Flushed, então um Buffer Flushed é emitido. Se o usuário a ser substituído não foi ET'd, esse usuário recebe um response code 9 subcode 15 é lançada para seu elemento fila do usuário para a sua próxima chamada Adabas. O utilizador recebe o código de resposta 9-15 não é necessariamente a causa mas a vítima. Se um usuário executa atualizações suficientes sem ET (e não excede um outro recurso, como a fila de Espera ou limite de tempo), então eles se pode receber um código de resposta 9-15. Veja mais Clique Aqui
Embora muitos fatores possam resultar no código de resposta 9-15, se o código de resposta 9-15 está ocorrendo e não é devido à extrema ou má codificação de aplicações, é um indicador de que Work Part 1 deve ser aumentada.
Uma escola de pensamento sobre o dimensionamento da Work Part 1 diz que o Work Part 1 deve ser quatro vezes (em volta de 25%) do montante máximo de transações correntes vezes os updates média por tempo de transação dos bloco da Work medio por atualização. Este seria um dimensionamento mínimo. Note-se que o dimensionamento de ADARUN NISNHQ afeta essa fórmula.
Outra escola de pensamento sobre o dimensionamento da Work Part 1 diz que, em um cenário de pior caso, a área pode ser dimensionada como o número máximo de transações simultâneas vezes o ADARUN TT= dividido pelo tempo médio de uma I/O da Work (ver estatísticas de cache abaixo como obter o tempo médio de trabalho I/O). Note-se que o dimensionamento de ADARUN TT afeta essa fórmula.
Fatores (alterações no ambiente das aplicações) podem aumentar cenários de Response Code 9-15 9-15 (ou aumentam a necessidade de aumentar Work Part 1) podem incluir, mas não se limitando ao seguinte:
- Aumente o Limite de Tempo Maior transação (ADARUN TT=)
- Aumento atualizações por transação (ADARUN NISNHQ =)
- Aumento comprimido tamanhos de registro, o aumento descritores e atualizações de descritores
- Aplicações batch que atualizam sucessivamente menores valores de descritores (aumenta blocos splits)
Uma Work Part 1 pequeno Aumenta Buffer Flushes #
Veja a explicação acima sobre o que acontece no local de Work Wraparound. Há gráficos que mostram como o aumento Work Parte1 diminui descargas do buffer (e melhora o desempenho do banco de dados), mas eu não poderia facilmente copiar gráficos Xcel neste meio.
Aumentando a Work Part 2 (Adarun LWKP2=)
A Work Part 2 é usado como uma área de rascunho baseado em disco para processar o comando Sx (FIND). A quantidade de Work Part 2 usada por qualquer comando único é apenas para a duração desse comando no segmento Adabas. Vários comandos Sx em vários segmentos usará simultaneamente a Work Part 2. O dimensionamento de ADARUN LWP e ADARUN LS afeta diretamente o quanto esta área é usada (como esses parâmetros aumentado, o uso da Work Part 2 pode diminuir).
- Tamanho mínimo: 0 blocos
- Tamanho máximo: 16,7 milhões de blocos
- Tamanho padrão: (veja abaixo) NÃO USE default
Uma tabela interna Adabas requer um byte de armazenamento para cada Work part 2 bloco.
Se a Work Part 2 é muito grande pode afetar os requisitos de memória (1 byte por Work Part 2). Se o trabalho da Parte 2 é armazenado em cache (ADARUN CWORK2FAC=), então um grande Work Part 2, com uma grande CWORK2FAC correspondente = pode voltar a afetar os requisitos de memória.
Note-se que até mesmo a utilização de uma pequena CWORK2FAC (1%) pode indicar uso da Work Part 2.
Se a Work Part 2 é muito pequena.
Ocorre atraso do comando Sx (FIND)
Response Code 74 (Work Part 2 está cheia)
O código da aplicação deficiente pode afetar o tamanho da área. Por exemplo, os programas podem estar fazendo desnecessariamente grandes pesquisas complexas (o que inclui pesquisas em não descritores).
Padrão Dimensionamento de Work Part 2
WORK2 = 22 + 2 * (4 * RECORDS / (BLKSIZE - 16))- Work2 é work part 2 que necessita de espaço em blocos.
- BLKSIZE é o tamanho do bloco do dispositivo dataset da Work
- RECORDS é o número de registros no arquivo com a maioria dos registros. Este número é igual TOPISN - MINISN + 1, em que é o mais alto TOPISN ISN atualmente utilizado no arquivo. MINISN é o menor ISN usado no arquivo. Note-se que TOPISN é avaliada na inicialização do banco de dados.
Parm Error 18 na Inicialização do banco Adabas
Isso ocorre principalmente quando o tamanho padrão da Work part 2 é usado. O cenário é o banco de dados entra no ar e a Work Part 2 foi dimensionada pela maior TOPISN existente. Em algum momento durante a sessão Adabas, um arquivo no banco de dados aumenta significativamente o TOPISN (via inserções de registro ou carregando um arquivo muito maior para o banco de dados). A próxima vez que o banco de dados for iniciado, uma tentativa é redimensionar Work part 2 pelo TOPISN maior e não há espaço no conjunto de dados Work para qualquer parte Work Work 2 ou a Work part 3 ficaram com menos de 50 blocos. Portanto, é importante que a Work part 2, LWKP2 =, é sempre usado.
Comando Sx (Find)
Nota: Os comandos complexos não são selecionados a partir da Command Queue (CQ) para o segmento Thread do Adabas a menos que 50% da Work part 2 esteja disponível. Portanto, o tamanho da Work part 2 em duas vezes é necessário para otimizar o processamento de comando de transferência. Esta é uma simples filosofia de negociação uma pequena quantidade de espaço em disco para o desempenho. Tipo de comando (complexo, atualização, simples) é determinada na rotina para ligação antes do comando é passado para Adabas. A decisão para comandos complexos é baseada nos comandos Sx cuja o comprimento Search Buffer excede um determinado constante. Devido à construção do comando Sx pelo Natural, todos comandos Sx/FIND no Natural são tratados como complexo (para fins de seleção de comando).
Fórmula para Tamanho do Work Part 2
WORK2 = S * 2 * ( 4*RECORDS / (BLKSIZE – 16)- Work2 é a Work part 2 é o espaço requerido em blocos;
- BLKSIZE é o tamanho do bloco do dispositivo do dataset de Work
- RECORDS é o número de registros no arquivo com a maioria dos registros. Este número é igual TOPISN - MINISN + 1, em que é o mais alto TOPISN ISN atualmente utilizado no arquivo. MINISN é o menor ISN usado no arquivo. * S é o número de comandos complexos simultâneas
S pode ser determinado através de estatísticas de encerramento do Adabas como o percentual de Sx comandos vezes o número de threads ativas (por exemplo. Se 10% dos comandos são Sx e há 10 threads ativas, então S seria de aproximadamente um valor de 1).
Aumentando a Work Part 3
A Work Part 3 é usado para listas de ISN resultantes do comando Sx/Find. Listas permanecem em Work Part 3 até que o último ISN é processado ou até que seja liberado pelo usuário (por exemplo,. comandos Via RC ou CL). Neste último caso, a lista ISN foi marcado (por exemplo, Opção. Comando 1 = H, ou o Natural "Reter o").
- Tamanho mínimo: 50 blocos (mais PARM-ERROR 18 no start do banco de dados)
- Tamanho máximo: desconhecido
O tamanho do Work Part 3 é o que resta em WORKSIZE depois da Work Part 1 e Work Part 2 foi feita sob medida. É fundamental que o dimensionamento do Work Part 1 e 2 não interferem com esta área.
Uma tabela interna do Adabas requer quatro bytes de armazenamento para cada block na Work part 3.
Se a Work Part 3 é muito grande pode afetar os requisitos de memória (4 bytes por Work Part 3). Se a Work Part 3 está em cache (ADARUN CWORK3FAC=), então um grande Work Part 3 com uma grande CWORK3FAC correspondente = pode voltar a afetar os requisitos de memória.
Note-se que até mesmo a utilização de uma pequena CWORK3FAC (1%) pode indicar uso da Work Part 3.
Se a Work Part 3 é muito pequeno um usuário receberá Response Code 73. O código da aplicação deficiente pode afetar o tamanho da área. Por exemplo os programas podem manter listas de ISN e não liberá-los. Consultas do tipo SQL pode criar extremamente grandes listas de ISN. Uso de grande algoritmo Sx/FIND pode esgotar nesta área (2 ou mais descritores, um valor cada).
Fórmula para Tamanho do Work Part 3
Existem várias fórmulas possíveis para usar em dimensionar esta área.
WORK3 = NU
WORK3 = NU * IU
WORK3 = NU * IU * AWBU
WORK3 = HIWATER.LI / ( 52 + 4 * NSISN)
WORK3 = ( HIWATER.LI / ( 52 + 4 * NSISN) ) * AWBU
AWBU = ISN.LIST.SIZE / BLKSIZE / 4- WORK3 é a Work part 3 requerida de espaço em blocos
- ISN.LIST.SIZE é o número médio de ISNS por lista
- AWBU é a parte de work média 3 blocos por lista (4 bytes por ISN)
- BLKSIZE é o tamanho do bloco do dispositivo do conjunto de dados Work
- NU é o ADARUN NU = valor. Isso pressupõe uma lista por usuário, uma bloco por lista na Work3. Ou pode-se usar a Highwater alta de NU.
- IU é as listas média ISN por usuário
- HIWATER.LI é a Highwater alta para a tabela de listas de ISN (ADARUN LI)
- NSISN é o valor ADARUN NSISN, o número de ISN do mantidos no quadro de entrada por ISN Listas
Note-se que o aumento NSISN diminuirá o uso da Work Part 3.
Aumentar o tamanho de bloco do dataset de Work
O tamanho do bloco do dataset de Work pode ser aumentado independentemente do Associator e do Datastorage (note que o PLOG precisara ser alteradas). Não pode haver ganho de desempenho significativo, aumentando o tamanho do bloco (redução do I/O) e quaisquer questões negativas são raras. Alterando o tamanho do bloco é o mesmo que o aumento do dataset de Work (ver acima). NOTA. O PLOG também terá que ter uma mudança no tamanho do bloco. Isso afetará o ADARUN DUALPLD e parms DUALPLS (menos blocos por o mesmo tamanho do PLOG).
Se o tamanho total do dataset de work é mantido, mas o tamanho do bloco foi aumentado, em seguida, os parms ADARUN de LP e LWKP2 terá de ser ajustado para baixo. A outra abordagem é aumentar o dataset de Work ao mesmo tempo do aumento do tamanho de bloco.
Dividindo o dataset de Work em vários volumes
Historicamente, em alguns locais de trabalho já vi vantagens de desempenho em dividir em três partes a work em vários volumes. Outras soluções para isso são a cache do Work Part 2 e 3 (ver abaixo). Além disso, a utilização do PAV (Parallel Access Volumes) poderia eliminar a necessidade deste.
Work Caching Part 2 e 3
ADARUN CWORK2FAC e CWORK3FAC
Veja outras fontes sobre os tipos de cache, relatórios, problemas, entre outros. Um cache mínima de 1% é recomendado para cada um como este fornece muitas estatísticas úteis em IO de por área Work, tempos de I/O relativos, etc. O seguinte é uma exposição de cache amostra (disponível via comandos do operador, AOS, lote ADADBS OPERCOM, ou estatísticas de desligamento do banco de dados.
+--------------------------------------------------------+
+,Work2,Virtual 64, RABNS 83,702 thru 84,301 +
+--------------------------------------------------------+
+ allocated, LA=10:07:25 +
+--------------------------------------------------------+
+ 360 Cache Writes 5 Blks in Cache +
+ 91 Read EXCPS + 16,797,696 V64 Size +
+ 2,491 Cache Reads + 600 Blks/V64 +
+ 2,582 Total Reads + 4,816 RABN Tab Size +
+ 96.4 V64 Efficiency+ 139,950 Max V64 Used +
+ 0.064275 Max NIOT (Sec)+ 0.033263 Max EXCPT(Sec)+
+ 0.000010 Min NIOT (Sec)+ 0.001111 Min EXCPT(Sec)+
+ 0.000103 Ave NIOT (Sec)+ 0.004797 Ave EXCPT(Sec)+
+--------------------------------------------------------+
+--------------------------------------------------------+
+ Work3 Virtual 64, RABNS 89,702 thru 89,998 +
+--------------------------------------------------------+
+ allocated, LA=19:56:18 +
+--------------------------------------------------------+
+ 45,758 Cache Writes 297 Blks in Cache +
+ 0 Read EXCPS + 8,314,880 V64 Size +
+ 974 Cache Reads + 297 Blks/V64 +
+ 974 Total Reads + 2,392 RABN Tab Size +
+ 100.0 V64 Efficiency+ 8,313,030 Max V64 Used +
+ 0.017694 Max NIOT (Sec)+ 0 Max EXCPT(Sec)+
+ 0.000011 Min NIOT (Sec)+ 0 Min EXCPT(Sec)+
+ 0.000086 Ave NIOT (Sec)+ 0.000000 Ave EXCPT(Sec)+
+--------------------------------------------------------+Checkilst para melhorar o desempenho da Work
- O dimensionamento correto da parte 1, 2, 3 Work (ver acima)
- Grandes blocos
- Cache da Work Part 2 e 3
- ADARUN NWORK1BUFFERS (geralmente aumentem)
- (Parallel Access Volumes) do PAV
- Sintonia geral dos discos do dataset de Work (i/o e do canal de contenção)
- O dimensionamento correto de LWP ADARUN e LS (geralmente aumentando)
- O dimensionamento correto de ADARUN NSISN (geralmente aumentando)
- O dimensionamento correto de ADARUN TT (geralmente diminui)
Determinando um ponto para Montagem da Work Part 1
Além da Software AG fornecer as informações, as seguintes rascunhos para uma maneira simples de verificar qual é o ponto envoltório é para as novas versões do Adabas.
- Criar um banco de dados dedicado para executar o teste para vários tamanhos de ADARUN LP (por exemplo, 200, 1000, 2000.)
- Crie um arquivo de registro grande (por exemplo, 100b campos, todos fixos, não descritores.). Tamanho do registro deve cerca fator em blocksize Work (por exemplo,. Work Blocksize de 5724, então o tamanho recorde de 1.300 bytes, 2 registros por bloco)
- Como o único usuário do banco de dados, execute um programa que insere registros no arquivo, contando o número de inserções de até um código de resposta 9 sub 15.
- Multiplique o número de inserções, vezes os registros por bloco; divida a Work Part 1 tamanho; então multiplicar por 100 (para um por cento) e que é o ponto aproximado envoltório.








0 comentários:
Enviar um comentário